Concepts#
This library is a collection of DataFusion extensions that enable distributed query execution. You can think of it as normal DataFusion, with the addition that some nodes are capable of streaming data over the network using Arrow Flight instead of through in-memory communication.
Key terminology:
Stage: a portion of the plan separated by a network boundary from other parts of the plan. A plan contains one or more stages, each separated by network boundaries.Task: a unit of work in a stage that executes a plan in parallel to other tasks within the stage. Each task in a stage runs on a different worker with its own plan variant — pre-specialized at planning time for the subset of data it is responsible for.Network Boundary: a node in the plan that streams data from a network interface rather than directly from its children nodes.Worker: a physical machine listening to serialized execution plans over an Arrow Flight interface. A task is executed by exactly one worker, but one worker executes many tasks concurrently.Leaf stage: a bottom stage of the plan — one that reads source data (e.g. aDataSourceExec).Head stage: the top stage, executed on a single task by the coordinator. Its output is what the client sees.
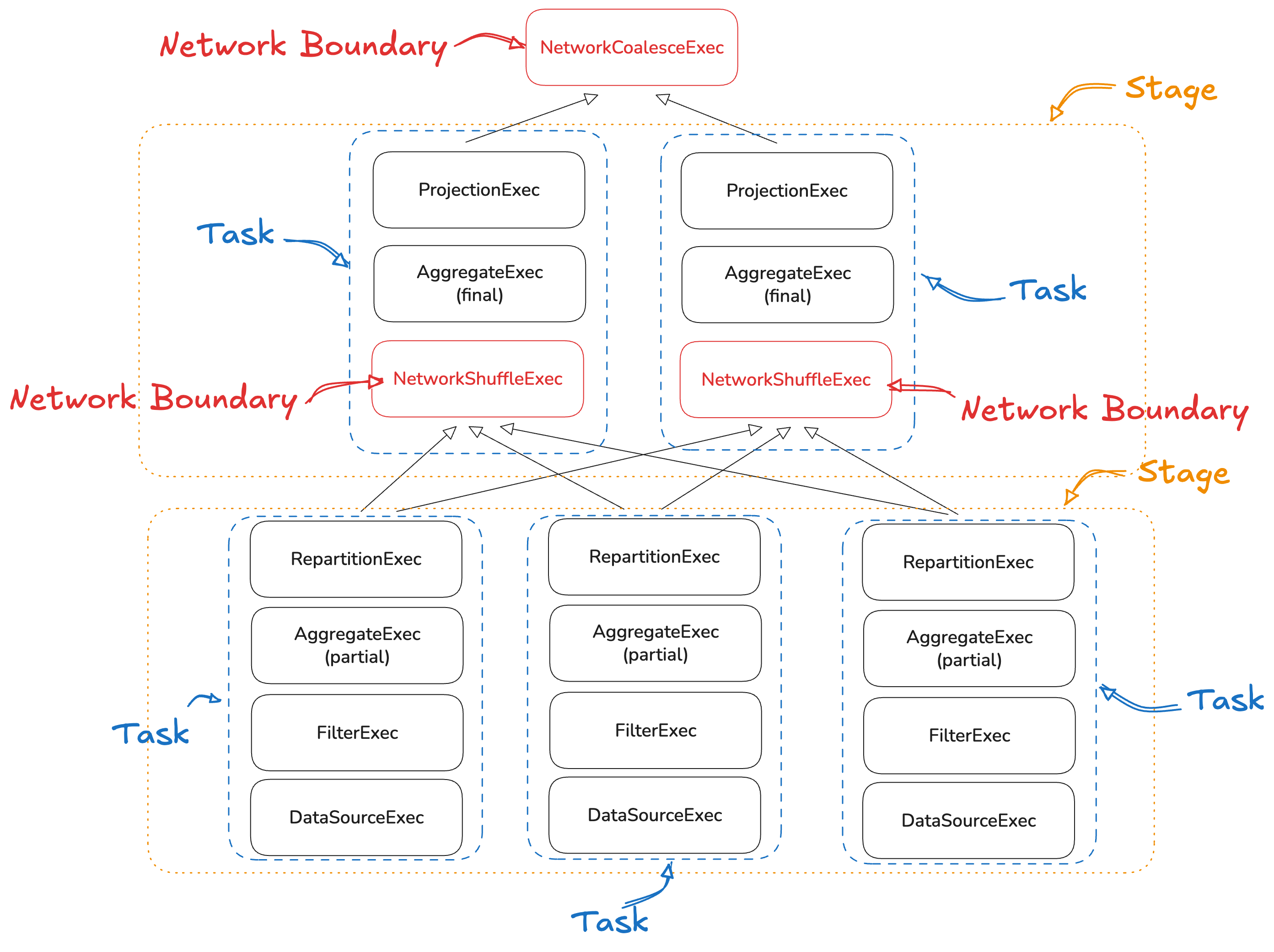
You’ll see these concepts mentioned extensively across the documentation and the code itself.
Coming from DataFusion?#
A distributed plan is a normal DataFusion physical plan with a few extra ExecutionPlan nodes inserted at
stage boundaries. If you already know DataFusion, this table is most of what you need:
Vanilla DataFusion |
Distributed DataFusion |
|---|---|
Partition (a thread on one machine) |
Task (a machine), each running its own partitions |
|
|
|
|
|
|
* BroadcastExec is a normal single-node operator (not a network boundary), even though it ships with this
project. It fills a gap in upstream DataFusion: broadcast repartitioning — copying every input partition to every
output partition — which RepartitionExec cannot express. NetworkBroadcastExec is what distributes it across
tasks.
The network boundary nodes execute their child on a remote worker over gRPC instead of in-process; everything else is the DataFusion you already know.
What you need (and what’s optional)#
To run distributed queries you need exactly three things:
with_distributed_planner()on the coordinator’sSessionStateBuilder— registers theQueryPlannerthat distributes the plan.A
WorkerResolver— tells the planner where the workers are.One or more
WorkergRPC servers running at those URLs.
Everything else is optional and only needed for specific cases:
A
ChannelResolver— a sensible default already exists.A
TaskEstimator— only for custom leafExecutionPlans; file-basedDataSourceExecis distributed out of the box.Work unit feeds — when a leaf’s work is discovered at runtime.
Manually injected network boundaries — for custom stage topologies.
Metrics collection — on by default.
Any custom
ExecutionPlanthat crosses a network boundary must have itsPhysicalExtensionCodecregistered on both the coordinator and everyWorker(see Spawn a Worker), since the node is serialized on one side and deserialized on the other.
Public API#
Some other more tangible concepts are the structs and traits exposed publicly, the most important are:
SessionStateBuilderExt#
An extension trait for SessionStateBuilder that provides with_distributed_planner(). This registers a custom
query planner that transforms single-node DataFusion query plans into distributed query plans after physical planning.
It builds the distributed plan from bottom to top, injecting network boundaries at appropriate locations based on the nodes present in the original plan.
Worker#
gRPC server implementation that integrates with the Tonic ecosystem and listens to serialized plans that get executed over the wire.
Users are expected to build these and spawn them in ports so that the network boundary nodes can reach them.
WorkerResolver#
Determines the available workers in the Distributed DataFusion cluster by returning their URLs.
Different organizations have different networking requirements—from Kubernetes deployments to cloud provider solutions. This trait allows Distributed DataFusion to adapt to various scenarios.
TaskEstimator#
Estimates the number of tasks required in the leaf stage of a distributed query.
The number of tasks each stage has is determined from bottom to top. This means that leaf stages will decide how many tasks they need to execute based on the amount of data their leaf nodes will pull. Upper stages will have their number of tasks reduced or increased depending on how much the cardinality of the data was reduced in previous stages.
DistributedTaskContext#
An extension present during the ExecutionPlan::execute() that contains information about the current task in
which the plan is being executed.
For built-in file-based plans (DataSourceExec), data partitioning is handled automatically at planning time via
DistributedLeafExec: each task receives a pre-built plan variant with its own isolated file groups, so no
runtime dispatch is needed.
For custom leaf nodes that need to dispatch work themselves, DistributedTaskContext exposes task_index and
task_count so execution logic can select the appropriate data subset. For example, task 0 of 3 might return
the first third of rows, task 2 the last third, and so on. See the TaskEstimator documentation for guidance on
which approach to use.
ChannelResolver#
Optional extension trait that allows to customize how connections are established to workers. Given one of the
URLs returned by the WorkerResolver, it builds an Arrow Flight client ready for serving queries.